MySQL索引的树立关于MySQL的高效运转是很重要的,索引能够大大提高MySQL的检索速度。
打个比如,假如合理的设计且运用索引的MySQL是一辆兰博基尼的话,那么没有设计和运用索引的MySQL便是一个人力三轮车。
拿汉语字典的目录页(索引)打比如,我们能够按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需求的字。
索引分单列索引和组合索引。单列索引,即一个索引只包括单个列,一个表能够有多个单列索引,但这不是组合索引。组合索引,即一个索引包括多个列。
创立索引时,你需求保证该索引是应用在SQL查询句子的条件(一般作为WHERE子句的条件)。
实践上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说运用索引的优点,但过多的运用索引将会造成乱用。因而索引也会有它的缺点:尽管索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不只要保存数据,还要保存一下索引文件。
树立索引会占用磁盘空间的索引文件。
普通索引
创立索引
这是最基本的索引,它没有任何约束。它有以下几种创立方法:
CREATEINDEXindexNameONtable_name(column_name)
假如是CHAR,VARCHAR类型,length能够小于字段实践长度;假如是BLOB和TEXT类型,有必要指定length。
修正表结构(增加索引)
ALTERtabletableNameADDINDEXindexName(columnName)
创立表的时分直接指定
CREATETABLEmytable(IDINTNOTNULL,usernameVARCHAR(16)NOTNULL,INDEX[indexName](username(length)));
删去索引的语法
DROPINDEX[indexName]ONmytable;
仅有索引
它与前面的普通索引相似,不同的便是:索引列的值有必要仅有,但允许有空值。假如是组合索引,则列值的组合有必要仅有。它有以下几种创立方法:
创立索引
CREATEUNIQUEINDEXindexNameONmytable(username(length))
修正表结构
ALTERtablemytableADDUNIQUE[indexName](username(length))
创立表的时分直接指定
CREATETABLEmytable(IDINTNOTNULL,usernameVARCHAR(16)NOTNULL,UNIQUE[indexName](username(length)));
运用ALTER指令增加和删去索引
有四种方法来增加数据表的索引:
ALTERTABLEtbl_nameADDPRIMARYKEY(column_list):该句子增加一个主键,这意味着索引值有必要是仅有的,且不能为NULL。
ALTERTABLEtbl_nameADDUNIQUEindex_name(column_list):这条句子创立索引的值有必要是仅有的(除了NULL外,NULL可能会呈现多次)。
ALTERTABLEtbl_nameADDINDEXindex_name(column_list):增加普通索引,索引值可呈现多次。
ALTERTABLEtbl_nameADDFULLTEXTindex_name(column_list):该句子指定了索引为FULLTEXT,用于全文索引。
以下实例为在表中增加索引。
mysql>ALTERTABLEtestalter_tblADDINDEX(c);
你还能够在ALTER指令中运用DROP子句来删去索引。测验以下实例删去索引:
mysql>ALTERTABLEtestalter_tblDROPINDEXc;
运用ALTER指令增加和删去主键
主键作用于列上(能够一个列或多个列联合主键),增加主键索引时,你需求保证该主键默认不为空(NOTNULL)。实例如下:
mysql>ALTERTABLEtestalter_tblMODIFYiINTNOTNULL;mysql>ALTERTABLEtestalter_tblADDPRIMARYKEY(i);
你也能够运用ALTER指令删去主键:
mysql>ALTERTABLEtestalter_tblDROPPRIMARYKEY;
删去主键时只需指定PRIMARYKEY,但在删去索引时,你有必要知道索引名。
显现索引信息
你能够运用SHOWINDEX指令来列出表中的相关的索引信息。能够通过增加G来格式化输出信息。
测验以下实例:
mysql>SHOWINDEXFROMtable_nameG
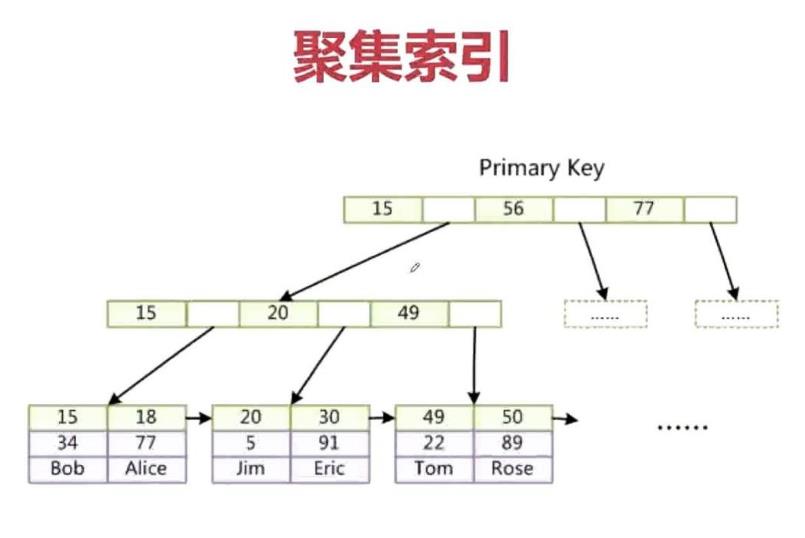
mysql索引实现原理
什么是索引:
索引是一种高效获取数据的存储结构,例:hash、二叉、红黑。
Mysql为什么不必上面三种数据结构而选用B+Tree:
若仅仅是select*fromtablewhereid=45,上面三种算法可以轻易实现,但若是select*fromtablewhereid<6,就不好使了,它们的查找方法就类似于”全表扫描”,由于他们的高度是不可控的(如下图)。B+Tree的高度是可控的,mysql一般是3到5层。注意:B+Tree只在最末端叶子节点存数据,叶子节点是以链表的形势相互指向的。
B+Tree的特性
(1)由图能看出,单节点能存储更多数据,使得磁盘IO次数更少。
(2)叶子节点形成有序链表,便于履行范围操作。
(3)集合索引中,叶子节点的data直接包括数据;非集合索引中,叶子节点存储数据地址的指针。
回到顶部
Innodb引擎
若以这个引擎创立数据库表Createtableuser(…..),它实际是生成两个文件:
user.ibd表索引和数据文件user.frm表结构类型
由于innodb引擎创立表默许便是以主键为索引,所以不需求myi文件。
下图为innodb表的结构图:
若此刻,你在其他列创立索引例如name,它就会另外创立一个以name为索引的索引树,(叶子节点存的是索引和主键索引)。
你在履行select*fromuserwherename=‘吴磊’,他的履行过程如下:
(1)找到name索引树
(2)根据name的值找到该树下叶子的name索引和主键值
(3)用主键值去主键索引树去叶子节点到该条数据信息
MyISAM引擎和InnoDB引擎的区别
MyISAM:支撑全文索引;不支撑业务;它是表级锁;会保存表的详细行数.
InnoDB:5.6以后才有全文索引;支撑业务;它是行级锁;不会保存表的详细行数.
一般:不必业务的时分,count核算多的时分适合myisam引擎。对可靠性要求高便是用innodby引擎。推荐用InnoDB引擎.
加了索引之后能够大幅度的进步查询速度,可是索引也不是越多越好,一方面它会占用存储空间,另一方面它会使得写操作变得很慢。一般咱们对查询次数比较频频,值比较多的列才建索引。
例如:select*fromuserwheresex=”女”,这个就不需求树立索引,由于性别总共就两个值,查询自身便是比较快的。
select*fromuserwhereuser_id=1995,这个就需求树立索引,由于user_id的值是非常多的。
回到顶部
磁盘数据页的存储结构
磁盘中的数据页是按次序一页一页寄存的,然后两两相邻的数据页之间会选用双向链表的格式相互引用。每一行数据都会按照主键巨细进行排序存储,一起每一行数据都有指针指向下一行数据的方位,组成单向链表。刚开始榜首行是个起始行,他的行类型是2,便是最小的一行,然后他有一个指针指向了下一行数据,每一行数据都有自己每个字段的值,然后每一行通过一个指针不断的指向下一行数据,普通的数据行的类型都是0,最后一行是一个类型为3的,便是代表最大的一行。
咱们刚说了,数据页中的数据行一定是按照主键巨细正序排列的。下一页的主键也一定会比上一页的大。如果咱们是自增还好,若是自己生成的则会呈现次序紊乱情况。mysql则会通过页分裂的机制将数据挪动到上一个数据页,确保下一个数据页里的主键值都比上一个数据页里的主键值要大。
回到顶部
主键索引页存储结构
主键索引的目录结构,只要在一个主键索引里包括每个数据页跟他最小主键值,就可以组成一个索引目录。然后后续你查询主键值,就可以在目录里二分查找直接定位到那条数据所属的数据页,接着到数据页里二分查找定位那条数据就可以了。
现在问题来了,你的表里的数据或许许多许多,比方有几百万,几千万,乃至单表几亿条数据都是有或许的,所以此刻你或许有很多的数据页,然后你的主键目录里就要存储很多的数据页和最小主键值,这怎么行呢?所以在考虑这个问题的时分,实际上是采取了一种把索引数据存储在数据页里的方法来做的。也便是咱们上面提到的b+tree结构。
比方我现在要找id=45的数据,就会先从35页找到23页,再找到6页,最后找到第4页。然后它就指向了叶子节点(数据页)。
若是你基于非主键字段name树立了一个索引,那么此刻你刺进数据的时分,就会从头搞一颗B+树,B+树的叶子节点也是数据页,可是这个数据页里仅仅放主键字段和name字段、数据行按name巨细排列,就不是详细数据了。先找到name对应的主键地址,再去主键索引树找到详细数据信息。这种行为叫做回表查询(若select的所有字段都是索引中的字段则直接就返回了,不必去主键索引树中找了。这种行为叫做覆盖索引)